It is not only a fully functional graph visualization library, but also an explorer of data relationships.
!!!###!!!title=Intelligent Data Aggregation——VisActor/VMind tutorial documents!!!###!!!
Data Aggregation
Overview of Data Aggregation
When we use chart libraries like VChart to draw bar charts, line charts, etc., if the dataset used has not been aggregated, it may have a negative impact on the visualization effect.
For example, suppose we have a product sales detail dataset:
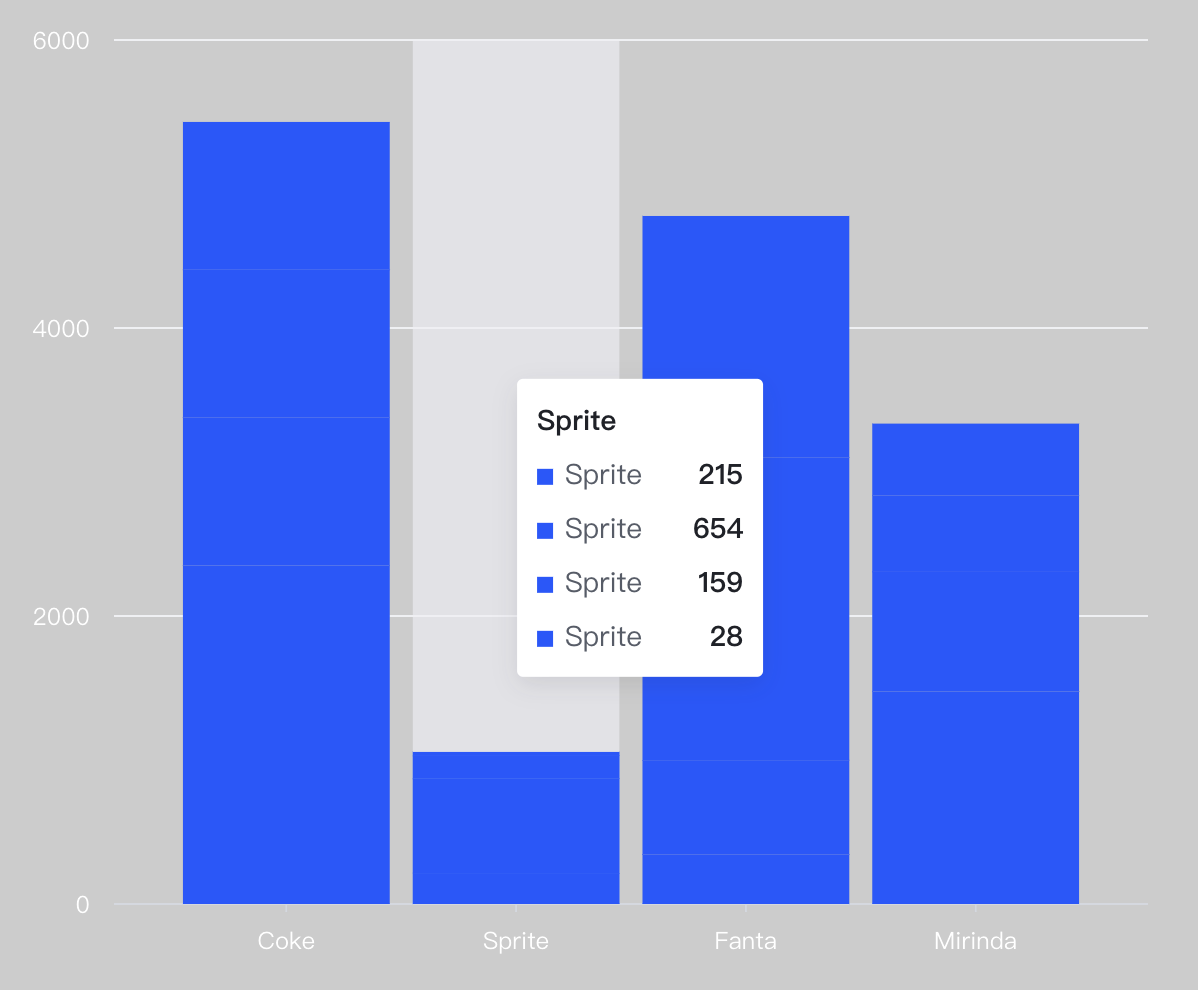
In this dataset, there are two fields Product name and Sales. It can be seen that in this dataset, multiple data have the same Product name. If we want to use this data to draw a bar chart with Product name as the X-axis and Sales as the Y-axis to show the sales in different regions, there will be multiple bars corresponding to each dimension value on the X-axis.
Different chart libraries handle this kind of dataset differently. VChart's approach is to stack these bars for display:
Drawing charts with this unaggregated dataset may have the following problems:
Data overload: If the dataset is very large, there may be a large number of graphic elements in the chart, which may make the chart very chaotic, difficult to read and understand, and cause performance problems.
Hiding important information: If the data has not been properly aggregated, it may hide some important information. For example, if you have a dataset containing daily sales, drawing this dataset directly may make the chart very chaotic. However, if you aggregate the data by month, it may be easier to see the trend of sales.
Unclear data distribution: Unaggregated data may make the distribution characteristics of the data unclear, such as the average, median, mode, etc.
Therefore, we usually aggregate the data appropriately before drawing the chart to better display the characteristics and trends of the data.
At the same time, because the original dataset does not filter and sort the fields, some chart display intentions cannot be met, such as: show me the 10 departments with the highest sales, show me the sales of various products in the northern region, etc.
Starting from version 1.2.2, VMind supports the intelligent data aggregation function. This function takes the data input by the user as a data table, generates SQL query statements according to the user's instructions using the large language model, queries data from the data table, and uses GROUP BY and aggregate functions to group, aggregate, sort, and filter the data.
Next, we will detail the usage of the VMind data aggregation function.
dataQuery
The dataQuery function of the VMind object is a powerful data aggregation tool. It takes three parameters: userPrompt for user display intent, fieldInfo for dataset field information, and the original dataset. Detailed information about fieldInfo and dataset can be found in Data Format and Data Processing. VMind will write SQL statements based on the user's display intent, execute queries on the dataset, and the query results will be stored in the dataset property of the function return value; at the same time, the fields in the query results may change, and the updated field information will also be stored in the fieldInfo property of the return result.
Next, let's see how to use the dataQuery function through an example:
[
{
"fieldName": "Product name",
"description": "The name of the product.",
"type": "string",
"role": "dimension" },
{
"fieldName": "total_sales",
"description": "An aggregated field representing the total sales of each product. It is generated by summing up the 'Sales' values for each product.",
"type": "int",
"role": "measure" }
]
With this information, we can directly use fieldInfo and dataset to generate charts. You can find the specific operation steps in the Intelligent Chart Generation section.
📢 Attention: The dataQuery method will pass the userPrompt and fieldInfo to the LLM to generate SQL, and the detailed data in the dataset will not be passed.
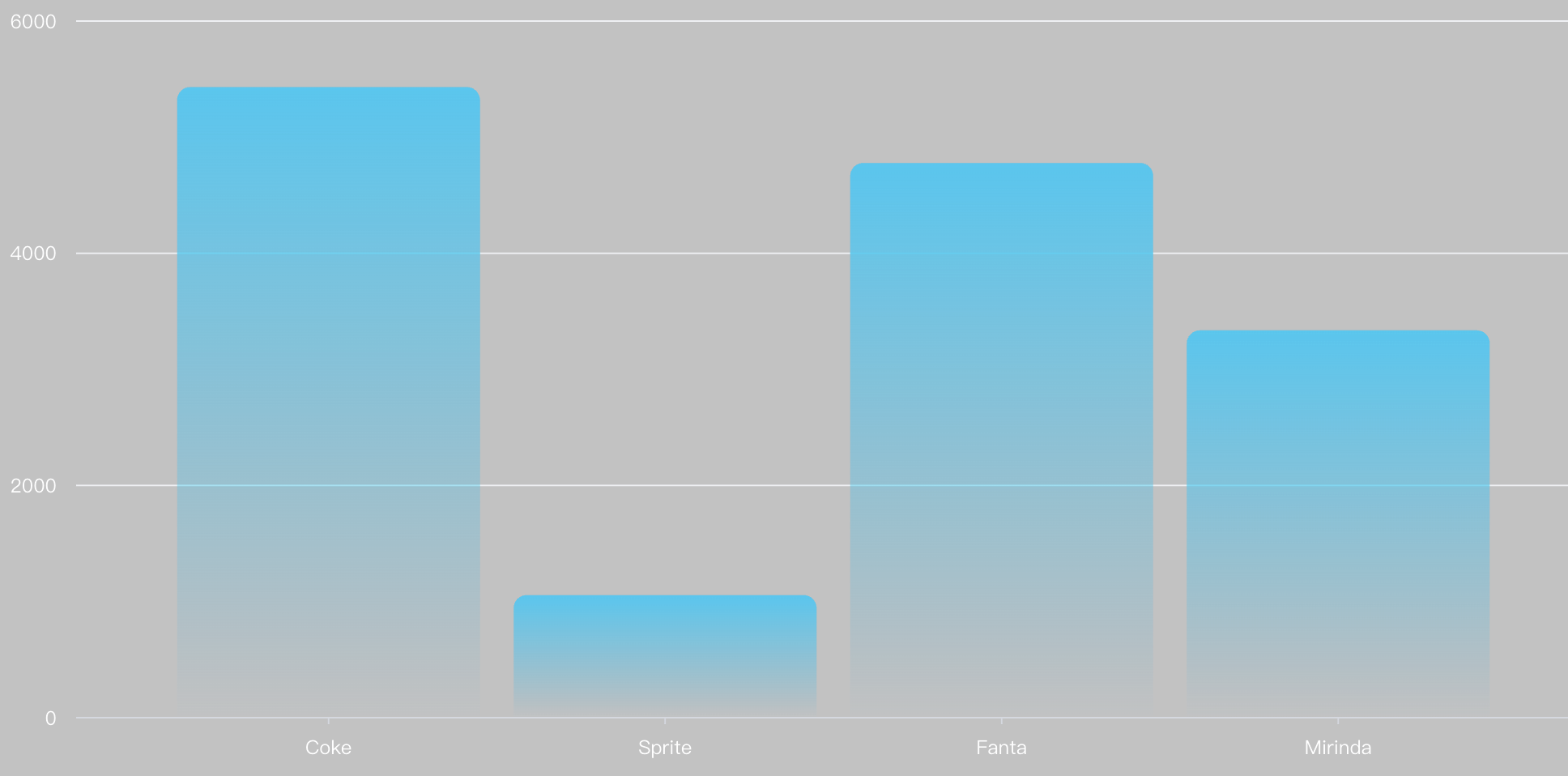
Finally, we will get the following bar chart:
In this example, the SQL statement generated by VMind is:
SELECT`Product name`, SUM(`Sales`) AS total_sales FROM dataSource GROUPBY`Product name`
This SQL statement selects the Produce name and Sales fields from the sourceDataset, groups by Produce name, and sums the Sales field to generate a new field total_sales. VMind will execute this SQL statement to get the aggregated dataset.
It should be noted that the SQL keywords currently supported in the dataQuery execution process are: SELECT, GROUP BY, WHERE, HAVING, ORDER BY, LIMIT. The currently supported aggregation functions are: MAX(), MIN(), SUM(), COUNT(), AVG(), but complex SQL operations such as subqueries, JOIN, conditional statements, etc. are not supported.
Data Filtering and Sorting
In this section, we will learn how to use natural language to perform operations such as filtering and sorting on the dataset.
First, let's take a look at the following dataset and field information:
Suppose we want to show the top three products in terms of sales in the north region, we can do this:
const userPrompt = `Show me the top three products in terms of sales in the north`
const vmind = new VMind(options)
// Call the dataQuery method, pass in userPrompt, sourceFieldInfo, and sourceDataset toperform data aggregation
const { fieldInfo, dataset } = vmind.dataQuery(userPrompt, sourceFieldInfo, sourceDataset);
During the execution of the dataQuery method, the following SQL statement will be generated:
SELECT`Product name`, SUM(`Sales`) AS total_sales FROM dataSource WHERE region = 'north'GROUPBY`Product name`ORDERBY total_sales DESCLIMIT3
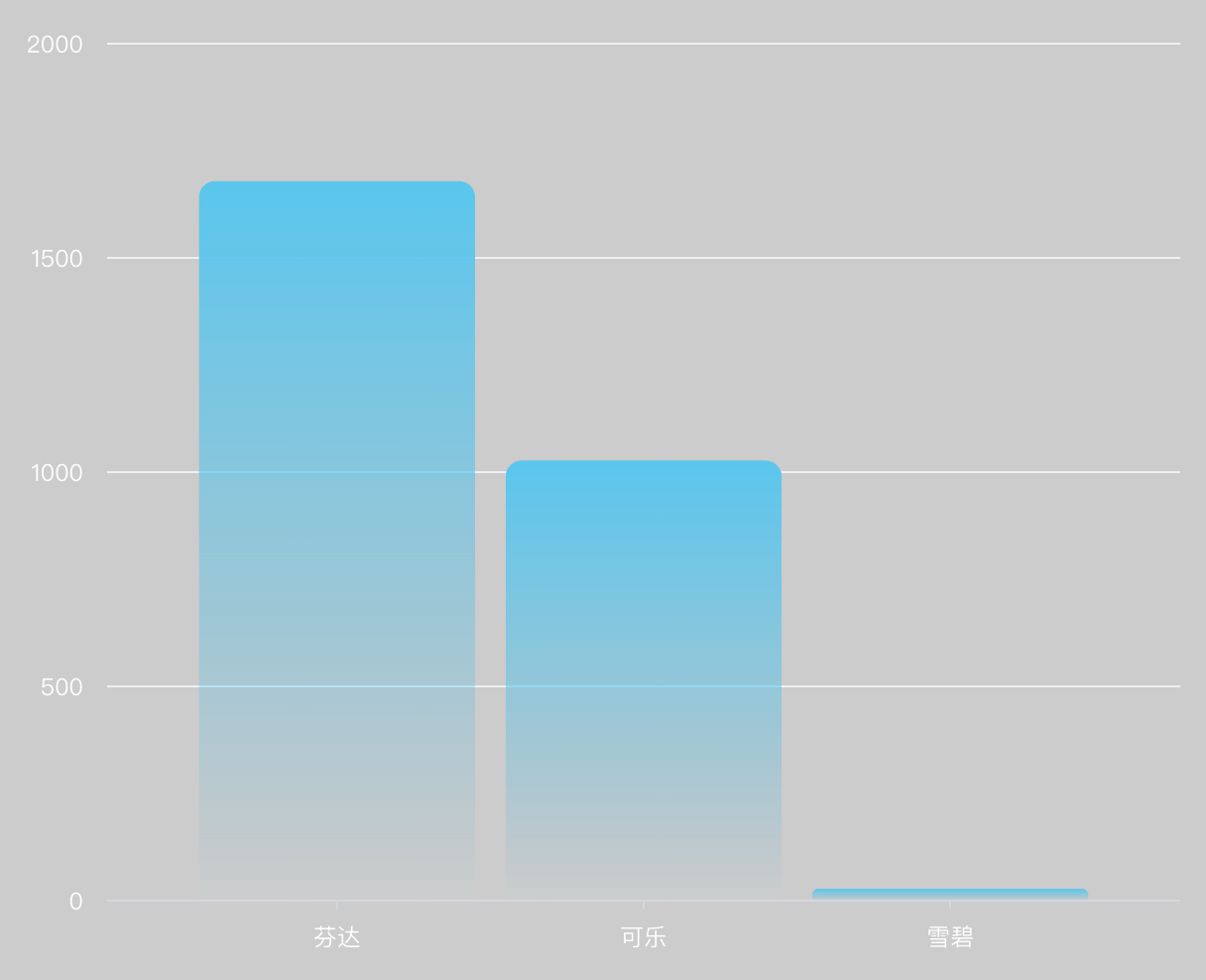
This SQL statement will filter out data where the region is 'north', then group by "Product name", and calculate the total sales of each product, finally sort by sales from high to low, and only take the top three products with the highest sales.
Finally, perform the chart generation operation, and we can get the following chart: