It is not only a fully functional graph visualization library, but also an explorer of data relationships.
!!!###!!!title=6.2 Basic Table Data Processing——VisActor/VTable Contributing Documents!!!###!!!!!!###!!!description=---title: 6.2 Basic Table Data Processing
key words: VisActor,VChart,VTable,VStrory,VMind,VGrammar,VRender,Visualization,Chart,Data,Table,Graph,Gis,LLM---
!!!###!!!
Introduction
For all tables, data sources are an essential part. @Visactor/VTable provides various data source structures, including two-dimensional arrays, object structures, tree structures, and asynchronous lazy-loaded data sources (https://visactor.com/vtable/guide/data/async_data). To adapt to so many data structures, a reasonable data processing module is needed, and @Visactor/VTable provides such capability internally. Let's see how basic tables parse data.
Core Classes Involved in Table Data Processing
VTable\packages\vtable\src\data\CachedDataSource.ts: CachedDataSource is responsible for intercepting incoming external records and provides APIs for adding, deleting, updating, and querying records; it wraps the DataSource with an additional layer.
VTable\packages\vtable\src\data\DataSource.ts: This class implements various data processing operations and maintains the raw data in dataSource.records to support dynamic updates of the table, as well as the underlying implementation logic of the CRUD API provided externally by the basic table instance. BaseTable will intercept modifications to the instance of DataSource to ensure that the basic table is re-rendered when dataSource is modified.
ListTable Data Parsing Principle
The previous article introduced the initialization process of ListTable [], which briefly mentioned the part related to records. Now, let's delve into the analysis of the data source parsing process of ListTable.
We will analyze with a simple case. The following code generates a basic table (since the process of parsing data involves sorting, sortState is added in the configuration to facilitate analyzing how sortState affects data parsing).
The initialization process has already been introduced in [], so the remaining processes will not be elaborated on. We will directly move on to the parts related to records. \r
packages\vtable\src\ListTable.ts
Here are three judgments made, two of which can be classified as one. Let's first look at the judgments of the following two branches.
First, clear the original dataSource, compatible with the previous sort configuration, and then clear all cell contents; \r
Next, update the internal this.sort through the stateManager.setSortState method to obtain the basic information of the cell corresponding to sort. In setSortState, the sort configuration is generated based on the passed sortState configuration and column information.
Enter the next branch and check if records exist. Both checks will enter _setRecords, and the only difference between the two checks is that if records are passed in, initial sorting will be performed based on the sortState and the sort configuration on the column. \r
_setRecords calls _dealWithUpdateDataSource, passing in a callback function; \r
In _dealWithUpdateDataSource, the first step is to remove all event listeners related to dataSource, the second step is to execute the passed callback function, and the third step is to bind the CHANGE_ORDER event to the dataSource. When the CHANGE_ORDER event is triggered, the table will be re-rendered. \r
Returning to the passed-in callback function, it first updates the records in internalProps, saving the original records passed in externally. Then it calls the CachedDataSource.ofArray method to obtain an instance of CachedDataSource, which is assigned to table.internalProps.dataSource; \r
Before parsing data in ofArray, getHierarchyExpandLevel is called to get the current tree structure's expand level, and it is passed as the last parameter to ofArray. \r
After _setRecords is completed, this.scenegraph.createSceneGraph() and this.render() are called to trigger table rendering.
Pass in dataSource
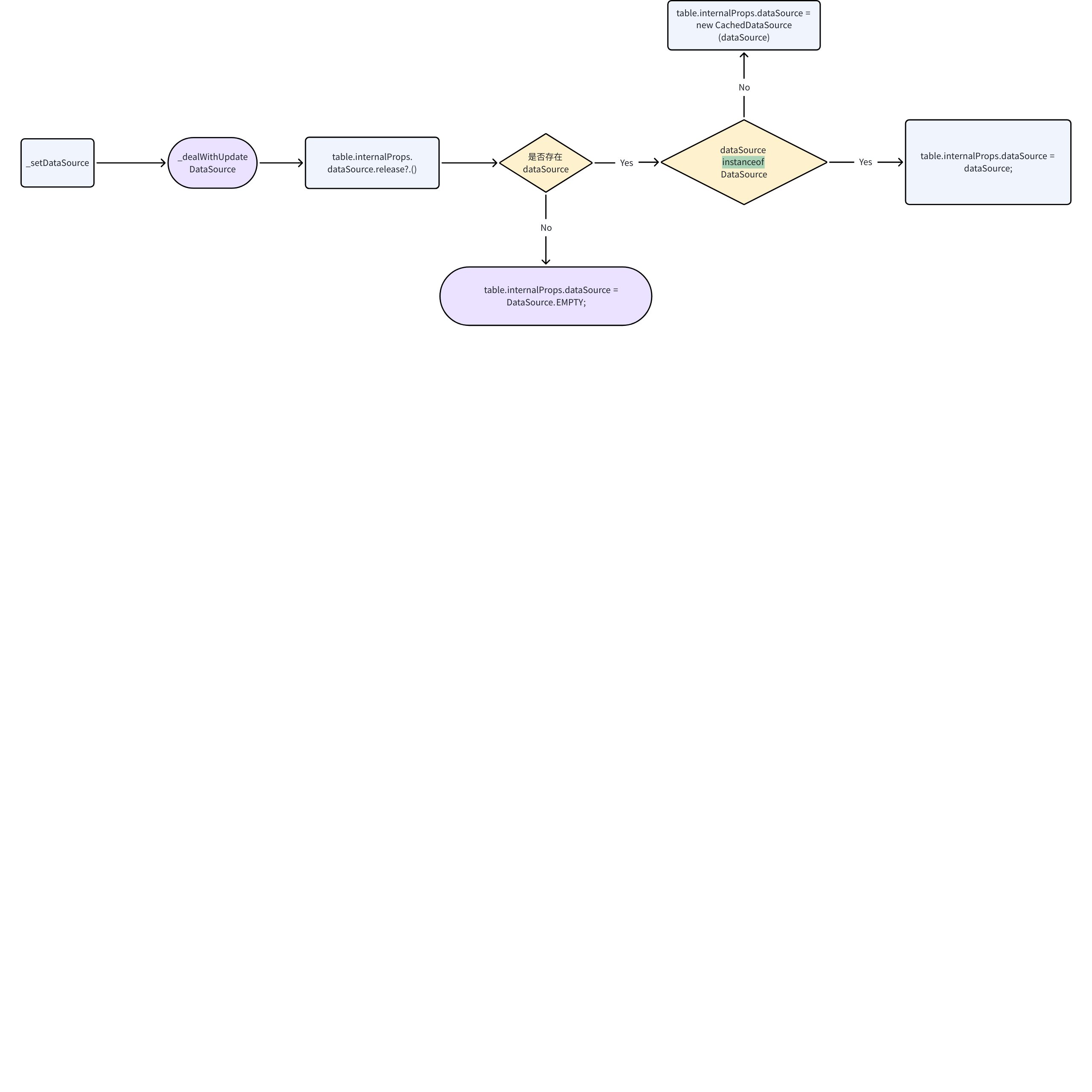
Since BaseTable implements the proxy for dataSource, when dataSource is passed in, it will directly follow the set dataSource process.
Compared to the _setRecords method that only receives records, when dataSource is passed in, VTable internally calls _setDataSource. The following diagram shows the process of _setDataSource. \r
After completing the initialization of dataSource, just like the latter part of the process of passing in records, set dataSource calls this.render() to trigger table rendering. This completes the data parsing of ListTable, where dataSource is mainly used for the parsing of the body in the basic table.
CachedDataSource Preprocessing
Summarizing the general data processing flow, we can get the following flowchart: \r
In summary, whether passing in dataSource or records, it inevitably involves CachedDataSource. Below is a detailed explanation of CachedDataSource. \r
CachedDataSource Core Processing
The previously mentioned situation of passing in records refers to the CachedDataSource.ofArray method. By observing the ofArray method, it is found that it essentially still uses new CachedDataSource, but adapts the records. The first parameter of the ofArray method is options.records. \r
Note that one of the parameters of CachedDataSource is passed with records. The reason for passing records will be explained later.
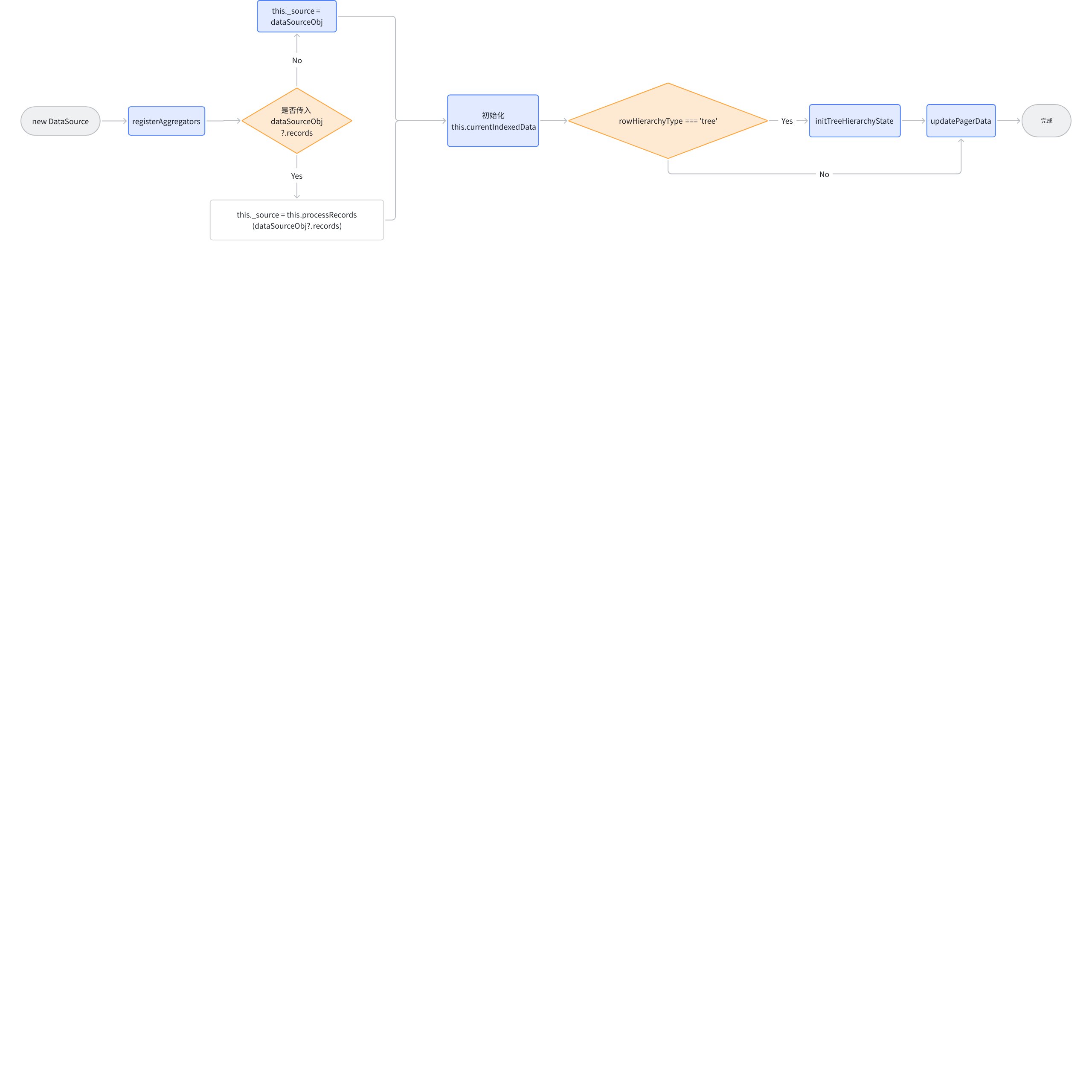
Observing the constructor of CacheDataSource, it can be found that CachedDataSource inherits from DataSource. When initializing CachedDataSource, the _isGrouped field is updated based on groupByRules, which will affect the call to getCellValue. After completing some basic operations, DataSource is directly initialized. \r
For basic table data processing, DataSource is the most important part, including the addition, deletion, modification, and query of records, as well as the value retrieval of the table body, all rely on this module. \r
DataSource supports six parameters during initialization
dataSourceObj: Data source object, which can internally pass in records. As mentioned earlier in the ofArray method, records will be carried within this parameter. \r
dataConfig: Data parsing configuration
pagination: current pagination configuration
columns: Current column configuration
rowHierachyType: The display form of the hierarchical dimension structure, either flat or tree structure. This configuration is only used in pivot tables. \r
hierarchyExpandLevel: The level of expansion for the tree structure, which will affect the initialization of the tree structure in initTreeHierarchyState \r
_source: ListTable stores the original records into DataSource._source, and implements a proxy for DataSource.records, accessing dataSource.records is actually accessing dataSource._source.
currentIndexedData: Each row corresponds to the index of the source data, which is a two-dimensional array structure used to store the indices of the displayed data, involving the basic layout of the table and data display. The following example shows currentIndexedData in a tree structure. The main data processing of ListTable, including the generation of the tree structure, retrieval of cell content, sorting, and the generation of _currentPagerIndexedData, all rely on this field. \r
For example, the DataSource.sort method actually sorts it, but does not update the passed-in records, only updates currentIndexedData;
For the use of currentIndexedData, you can refer to the DataSource.getValueFromDeepArray method. For example, to get the data of the second row, the reading method is records[0].children[0], which exactly corresponds to [0,0]
1. updatePagerData: By using the structure of the passed records and currentIndexedData, it updates _currentPagerIndexedData (*the index of the source data corresponding to each row of the current page*). This field is relied upon when performing CRUD operations on the data. After updating _currentPagerIndexedData, the initialization of the DataSource is complete. \r
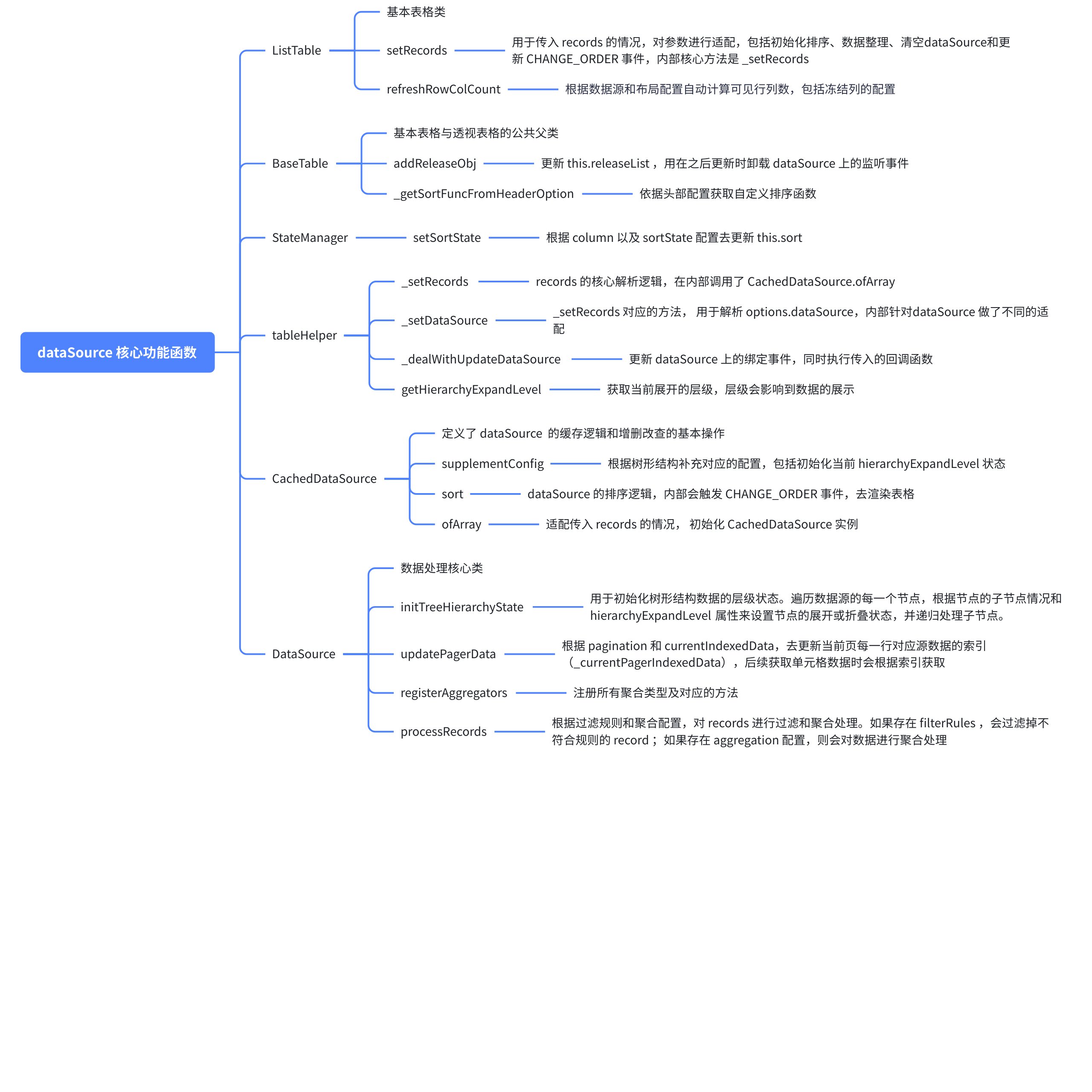
Analysis of Core Functional Functions Involved
The following diagram shows all the key functions and their roles mentioned earlier regarding the data parsing process. \r
Efficient Data CRUD Operations
Global Update and Local Update
Imagine how to efficiently update a table with a large number of columns without lagging. Common table component libraries based on Vue or React mostly rely on native DOM, which can utilize the built-in diff and update algorithms of VDom to achieve DOM reuse, enabling high-performance full data source updates. However, @Visactor/VTable is drawn based on canvas and does not have the concept of a virtual DOM, so achieving similar operations without affecting performance becomes a challenge. ListTable exposes many APIs for updating data sources, including full updates and partial updates. Let's look at how optimization is done internally in ListTable through some commonly used APIs.
addRecords
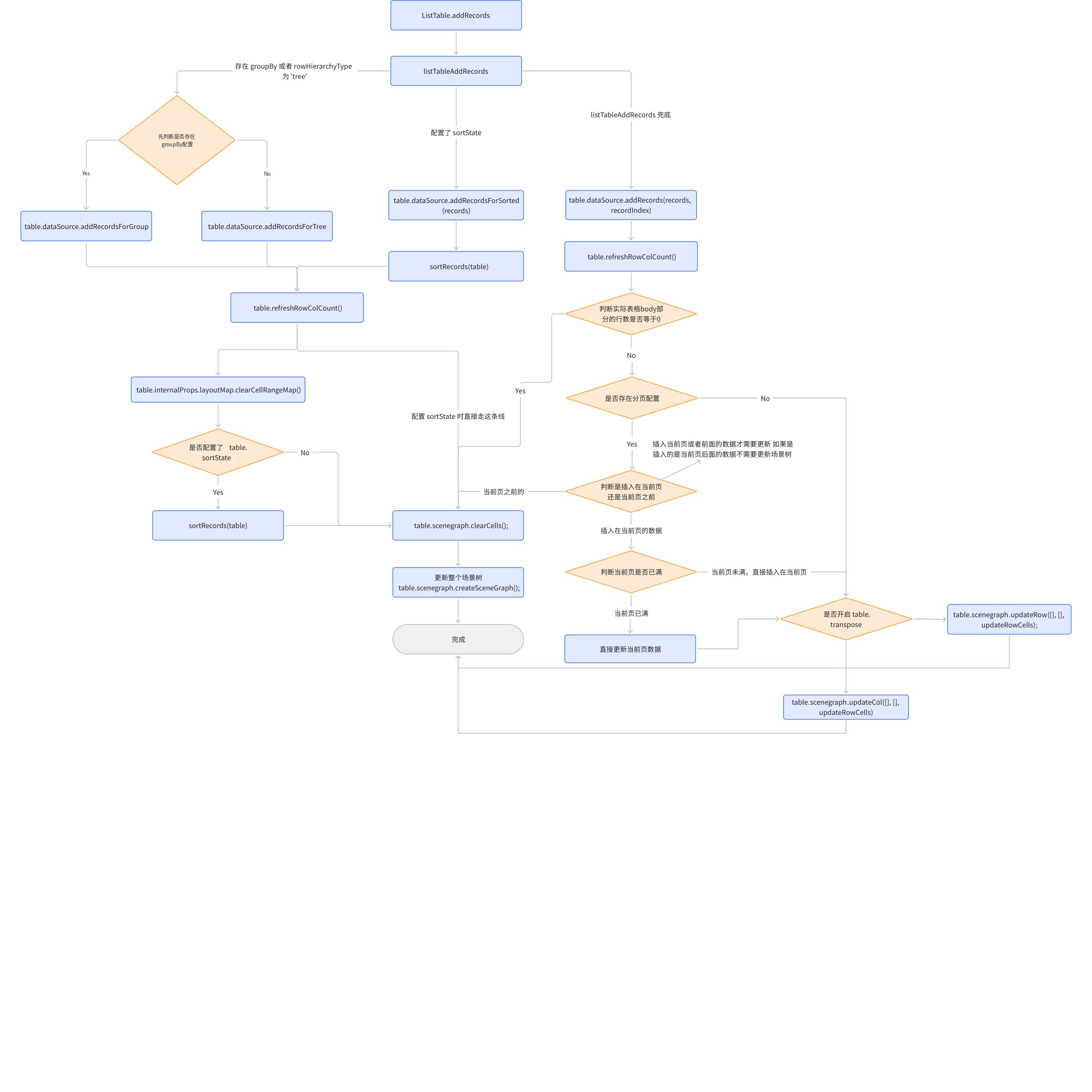
Reviewing the ListTable source code, we can easily see the definition of addRecords: \r
It contains four branches internally, the first two branches have the same logic, the only difference is whether to call dataSource.addRecordsForGroup or dataSource.addRecordsForTree. After the call is completed, the entire scene tree is updated directly.
The third branch checks the sortState, adds data and sorts it through dataSource.addRecordsForSorted, directly updating the entire scene tree.
The most important part is the last branch, which first calls dataSource.addRecords to add data, then calculates to determine which rows and columns actually need updating, and performs partial updates through updateCol or updateRow to reduce performance waste.
Features involved in DataSource
DataSource.addRecords: Add multiple data records in recordArr sequentially at the index position, while updating currentIndexedData and pagination data; \r
CachedDataSource.addRecordsForGroup: Append table data in the group; \r
DataSource.addRecordsForSorted: Clear the sortedIndexMap while updating records; \r
DataSource.addRecordsForTree: Adjust the tree structure expansion state while updating records; \r
addRecords Full Process
updateRecords
Think carefully, for data updates, is it similar to adding data? In some cases, there is no need to update the scene tree, just like addRecords, you can update specific rows directly. \r
Similar to addRecords, updateRecords is also defined in the ListTable class, and it can be seen that only listTableUpdateRecords is called inside updateRecords.
listTableUpdateRecords is generally similar to listTableAddRecords, both have four situations. In the first three situations, the scene tree will be directly updated. The difference lies in the default branch; listTableUpdateRecords will not calculate addRows, it will only calculate updateRowCells. \r
Features Involved in DataSource
DataSource.updateRecords: Modify records according to the index, and update currentIndexedData and pagination data; \r
CachedDataSource.updateRecordsForGroup: Update records and refresh Group status; \r
DataSource.updateRecordsForSorted: Clear the sortedIndexMap while updating records; \r
DataSource.updateRecordsForTree: Update records while adjusting the tree structure expansion state; \r
deleteRecords
deleteRecords is used to delete data from a specified index. Consider whether deleting data from a specified index can be similar to previous methods, where in some scenarios, the entire scene tree does not need to be updated. \r
DataSource.deleteRecords: Delete data from the specified index on records, while updating currentIndexedData and pagination data; \r
CachedDataSource.deleteRecordsForGroup: Delete records while refreshing the Group status; \r
DataSource.deleteRecordsForTree: Clear the sortedIndexMap while deleting records; \r
DataSource.deleteRecordsForTree: Adjust the tree structure expansion state while deleting records; \r
Data Update Principle
From the above commonly used APIs, the logic for data updates in ListTable is generally the same, consisting of four branches. In most scenarios, the default branch is entered, where methods in DataSource are first called to update records and currentIndexedData. Then, the actual rows that need to be updated are calculated. During the update, only scenegraph.updateCol is called to redraw the corresponding rows, thus achieving a DOM-like reuse operation. \r
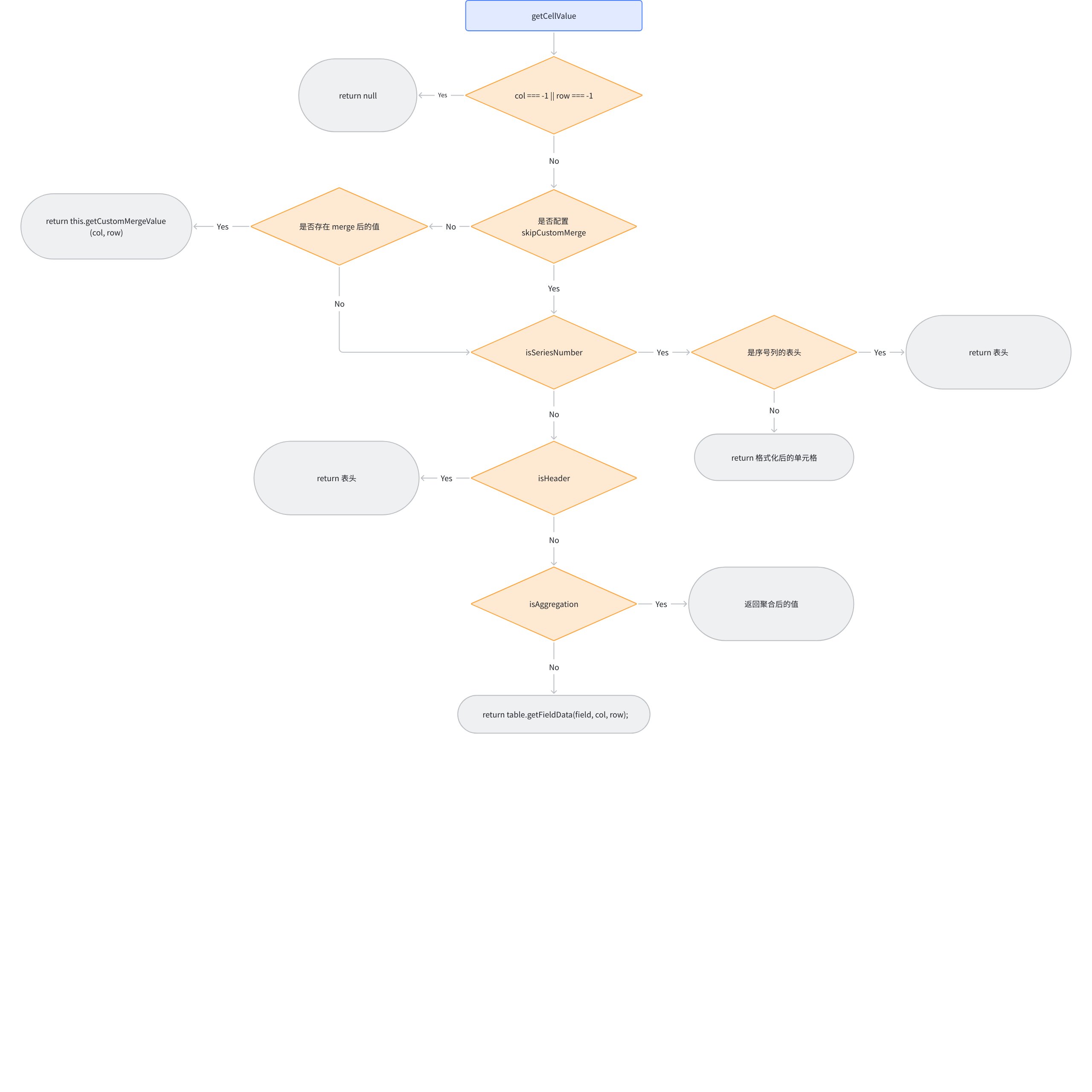
getCellValue
ListTable also provides us with the ability to obtain the display value of a cell. Now let's look at how to get the displayed data through pseudocode: \r
getFieldData internally calls the DataSource.getField method, which uses currentIndexedData to obtain the actual data index, thereby retrieving the actual data from the records. \r
Summary
Modular data processing: @Visactor/VTable separates the data processing of pivot tables and basic tables into two parts. Basic tables use DataSource and CachedDataSource, while pivot tables use a more complex DataSet class. This approach makes subsequent adjustments more convenient;
Data source abstraction: ListTable internally abstracts data through DataSource and CachedDataSource, placing all logic within the module to reduce cognitive load during data processing and achieve low coupling; \r
Efficient data processing: Since @Visactor/VTable is rendered based on Canvas, it cannot be manipulated like native DOM when updating data. ListTable cleverly avoids unnecessary rendering by calculating the rows that actually need to be updated and added, achieving efficient data processing.
This document is provided by the following personnel